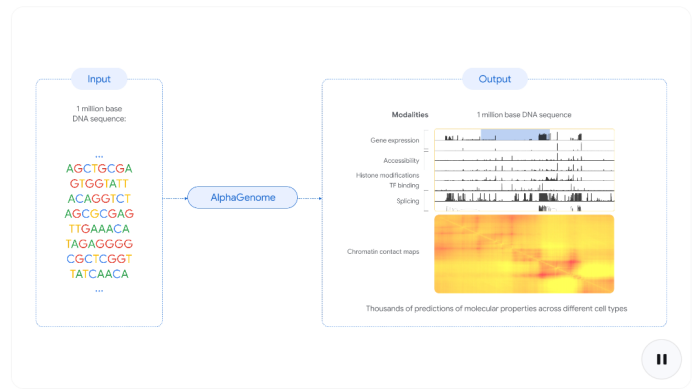
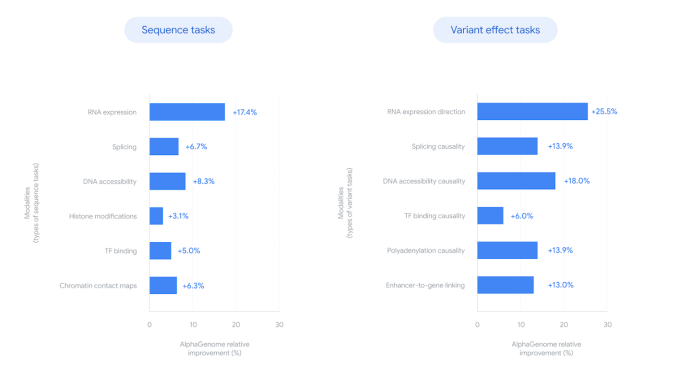
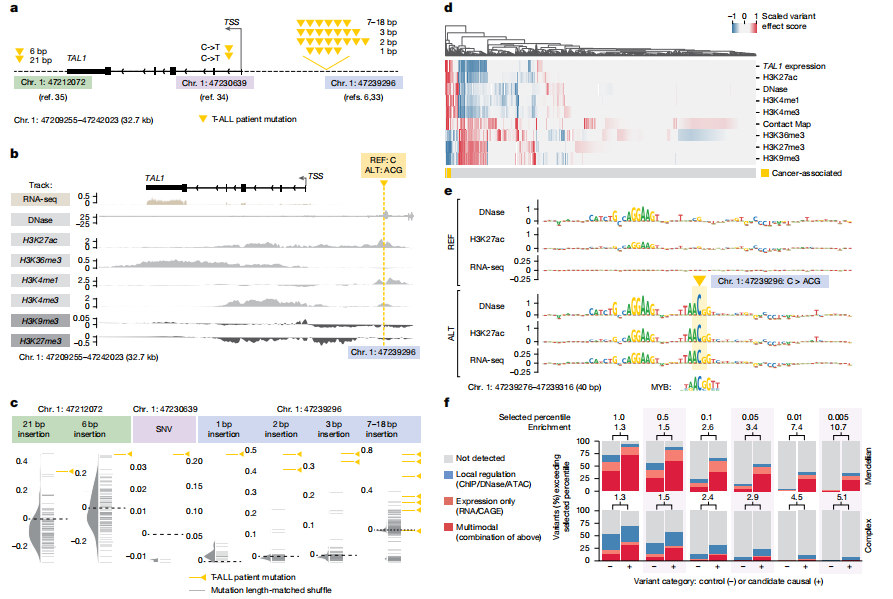
今天给大家分享谷歌Alpha系列新成员,“秒懂”生命终极蓝图,这项研究发布在Nature最新封面。 AlphaGenome 是一个能够统一预测长DNA 序列功能的深度学习模型。AlphaGenome的出现不仅为DNA序列建模设立了一个全新技术基线,也为生命科学研究者打开了一扇观察遗传调控全貌的新窗口。 01 基因组解读的挑战 人类基因组由约30亿个碱基对组成,其中仅有约2%编码蛋白质,而超过98%的非编码区域长期以来被称为"暗物质"。 这些非编码区域包含着调控基因表达的关键指令,但解读这些指令与表型之间的联系一直是生物学中最具挑战性的问题之一。 传统上,研究人员通过实验方法测量各种分子表型,如基因表达水平、染色质可及性、转录因子结合位点等,但这些方法成本高昂且耗时。 更为复杂的是,调控元素可能位于距离目标基因数万甚至数十万个碱基之外,而单个碱基的变异(单核苷酸多态性,SNP)可能通过改变转录因子结合、染色质结构或RNA剪接等方式影响基因功能。 02 AlphaGenome的诞生 AlphaGenome是Google DeepMind团队开发的一种统一DNA序列模型,旨在直接学习DNA序列与多种分子表型之间的关系。 与之前的方法相比,AlphaGenome解决了两个关键的技术权衡问题:序列长度与预测分辨率之间的权衡,以及多模态预测与专业化之间的权衡。 该模型接受长达1兆碱基(1 Mb)的DNA序列作为输入,并预测数千个功能基因组轨迹,分辨率达到单碱基水平。这些预测涵盖了11种不同的分子模态,包括基因表达(RNA-seq、CAGE、PRO-cap)、剪接(剪接位点、剪接位点使用、剪接连接)、染色质状态(DNase、ATAC-seq、组蛋白修饰、转录因子结合)和染色质接触图谱。 03 技术架构与创新 AlphaGenome采用了一种受U-Net启发的骨干架构,结合了卷积层和Transformer块。卷积层负责建模局部序列模式,这对于精细预测至关重要;而Transformer块则建模更粗糙但更长程的序列依赖性,如增强子-启动子相互作用。 该架构生成两种类型的序列表示:一维嵌入(1-bp和128-bp分辨率),对应线性基因组的表示;以及二维嵌入(2,048-bp分辨率),对应基因组片段之间空间相互作用的表示。 AlphaGenome的训练过程分为两个阶段:预训练和蒸馏。在预训练阶段,使用实验数据训练模型;在蒸馏阶段,训练一个单一的学生模型来预测多个教师模型集成的输出。 这种蒸馏方法不仅提高了模型的鲁棒性和变异效应预测准确性,还使预测效率大幅提升——在NVIDIA H100 GPU上,单次变异预测时间不到1秒。 04 性能表现:超越专业模型 研究团队对AlphaGenome进行了全面的性能评估,包括24个基因组轨迹预测任务和26个变异效应预测任务。 在基因组轨迹预测方面,AlphaGenome在22/24个评估中超越了现有最佳外部模型。特别值得注意的是,它在细胞类型特异性基因表达预测方面相对于Borzoi(另一种多模态序列模型)相对提高了14.7%。 在变异效应预测方面,AlphaGenome在25/26个评估中匹配或超越了最佳外部模型。这包括在表达数量性状位点(eQTL)符号预测方面相对于Borzoi提高了25.5%,以及在可及性QTL预测方面相对于ChromBPNet(平均跨五个数据集)提高了8.0%。 令人印象深刻的是,AlphaGenome甚至超越了针对特定任务优化的专业模型,如在接触图谱预测方面超越了Orca(接触图谱Pearson r +6.3%;细胞类型特异性差异+42.3%),在转录起始轨迹预测方面超越了ProCapNet(总计数Pearson r +15%)。 05 应用前景:从基础研究到疾病理解 AlphaGenome的预测能力可能推动多个研究领域的发展: 疾病理解方面,通过更准确地预测遗传破坏,AlphaGenome可以帮助研究人员更精确地定位疾病的潜在原因,并更好地解释与某些性状相关的变异的功能影响,可能发现新的治疗靶点。该模型特别适用于研究具有潜在大效应的罕见变异,如导致罕见孟德尔疾病的变异。 合成生物学方面,其预测可用于指导具有特定调控功能的合成DNA设计——例如,仅在神经细胞中激活基因而在肌肉细胞中不激活。 基础研究方面,它可以通过协助绘制关键功能元件并定义其角色,加速我们对基因组的理解,识别调节特定细胞类型功能的最基本DNA指令。 研究人员已使用AlphaGenome研究了癌症相关突变的潜在机制。在对T-ALL患者的研究中,AlphaGenome预测突变会通过引入MYB DNA结合基序激活附近基因TAL1,这复制了已知的疾病机制,并突出了AlphaGenome将特定非编码变异与疾病基因联系的能力。 06 当前局限与未来方向 尽管AlphaGenome代表了显著进步,但承认其当前局限性同样重要。像其他基于序列的模型一样,准确捕捉非常遥远的调控元件(如超过10万个DNA字母之外)的影响仍然是一个持续挑战。 另一个未来工作的优先事项是进一步提高模型捕捉细胞和组织特异性模式的能力。该模型尚未设计或验证用于个人基因组预测,这是AI模型的一个已知挑战。 虽然AlphaGenome可以预测分子结果,但它不能完全揭示遗传变异如何导致复杂性状或疾病。这些通常涉及更广泛的生物过程,如发育和环境因素,超出了模型的直接范围。 未来研究可能包括增加输入基因组多样性、整合单细胞数据、结合更广泛的数据模态(如DNA甲基化和RNA结构特征),以及利用DNA语言模型。 07 可用性与社区资源 DeepMind已通过AlphaGenome API提供该模型供非商业使用,并计划未来发布完整模型。研究人员可以通过社区论坛分享用例、提出问题或提供反馈。 团队还提供了基因组解释套件,便于探索和解释AlphaGenome,提供了一系列功能,如简化变异评分与分位数校准,以及通过基于ISM的实验中的贡献分数识别关键序列区域。 模型源代码、权重、变异评分实现以及选择的变异评估数据集和预测可在GitHub上获得。