DeepMind | Genie 3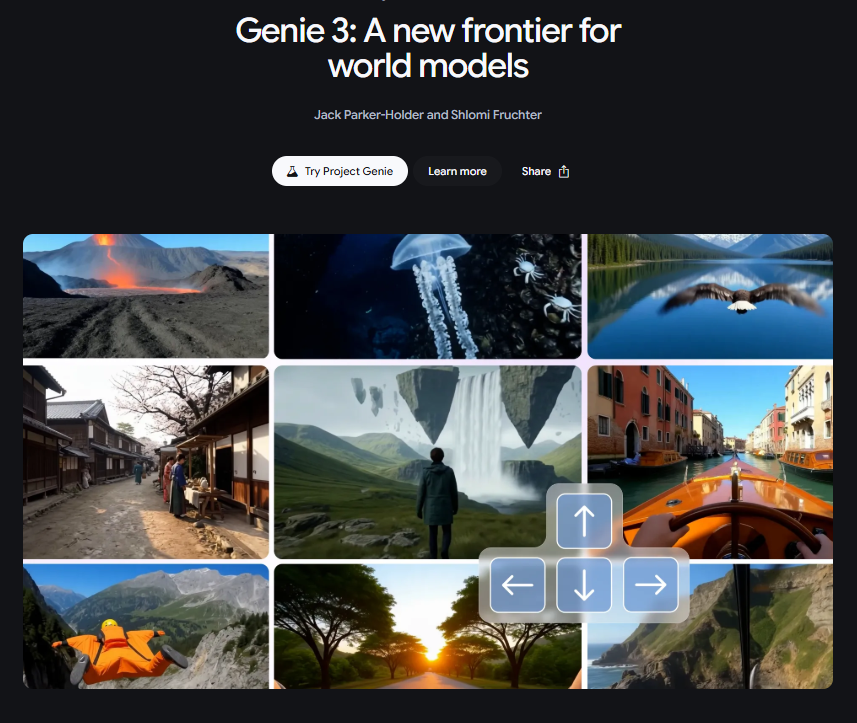

2025 年 8 月 5 日,Google DeepMind 正式发布 Genie 3—— 一款通用型世界模型,可通过文本提示生成前所未有的多样化交互式环境。它能以 24 帧 / 秒的速度支持 720p 分辨率的实时导航,场景一致性可持续数分钟,让 AI 对世界的模拟从 “静态生成” 跨入 “动态交互” 的全新阶段。
01 世界模型 AGI 征程的核心拼图
世界模型是 AI 理解并模拟现实的关键系统,能让智能体预测环境演化规律,以及自身行为对环境的影响。作为通往通用人工智能(AGI)的核心基石,它可为 AI 智能体打造无限丰富的模拟训练场景,摆脱对真实世界数据的依赖。 DeepMind 在该领域深耕十余年,从训练智能体攻克即时战略游戏,到开发机器人开放式学习模拟环境,逐步推进技术边界。此前推出的 Genie 1、Genie 2 奠定了基础世界模型的雏形,Veo 系列则在视频生成中展现了卓越的直观物理理解能力。 Genie 3 是 DeepMind 首款支持实时交互的世界模型,在一致性、真实感上全面超越 Genie 2;对比 GameNGen、Veo 等模型,其在控制精度、分辨率、交互延迟等核心指标上均实现显著突破。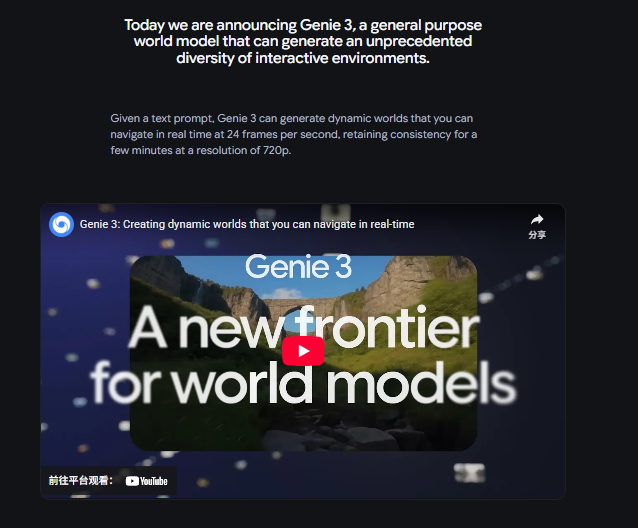
02 四大核心能力 贯通现实与想象
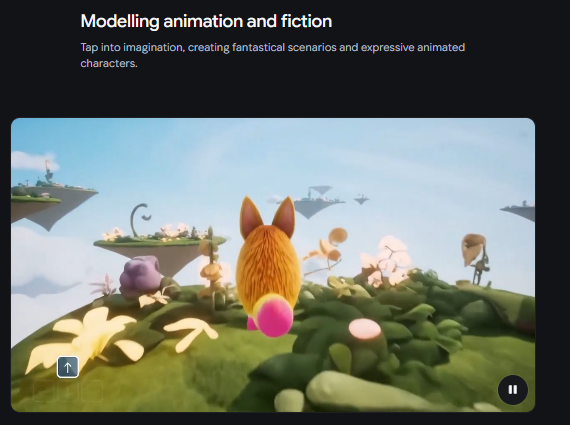
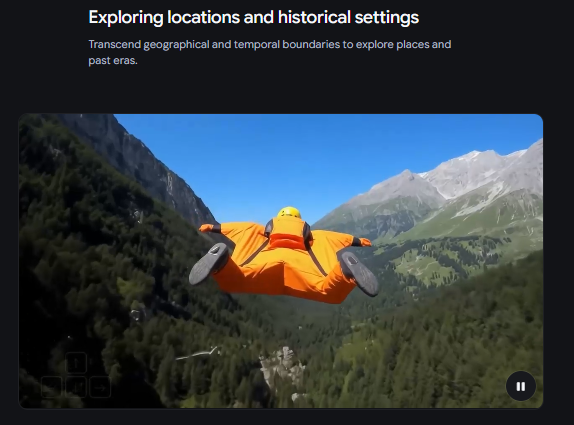
Genie 3 能精准覆盖从真实物理场景到奇幻虚构世界的全维度生成需求,核心能力集中在四大方向: 物理属性建模 精准还原水、光线等自然现象与复杂环境交互,例如模拟轮式机器人在火山地形规避熔岩池,还原轮胎碾压黑岩的质感与动态。 自然世界模拟 生成充满生机的生态系统,可呈现冰川湖畔的森林、积雪山脉的溪流,以及各类野生动物的自然行为。 动画与虚构创作 释放想象力,打造梦幻场景与鲜活角色,如毛茸茸的暖色调生物穿越彩虹桥的童趣画面,细节丰富且充满动态感。 时空场景探索 突破地理与时间限制,可生成阿尔卑斯山脉的险峻峡谷,也能还原古希腊神庙遗址等历史场景。

03 技术突破 交互与长期一致性的双重解
Genie 3 的核心突破,在于解决了 “动态生成 + 持续交互” 的两大技术难题: 实时响应能力:逐帧生成时会联动完整历史轨迹,即便用户一分钟后重返某一位置,模型也能精准调用过往信息,实现 24 帧 / 秒的流畅导航。 长期一致性:克服了逐帧生成的误差累积问题,场景可保持数分钟稳定,视觉记忆最长可达一分钟 —— 如古希腊神庙旁的树木,移出视野后再次出现仍与初始状态完全一致。 可提示世界事件:除基础导航外,支持文本指令动态修改环境,如切换天气、添加物体或角色,大幅拓展了 “反事实场景” 的模拟能力。 与依赖明确 3D 表示的 NeRF、高斯泼溅等方法不同,Genie 3 无需预设模型,完全基于文本描述和用户行为逐帧生成,场景的动态性与丰富度远超传统方案。 04 落地应用 从智能体训练到跨领域赋能 Genie 3 已展现出强大的应用潜力,尤其在 AI 研发与跨领域创新中价值突出: 具身智能体训练:成功适配 SIMA 智能体,支持智能体在生成环境中执行长序列动作,完成复杂目标。这为 AGI 训练提供了无限场景库,加速智能体能力迭代。 未来应用场景:可模拟火山、峡谷等危险环境,为教育提供沉浸式学习体验;能生成极端路况,助力自动驾驶系统安全训练;还可为影视、游戏创作提供快速场景原型,大幅降低创意落地成本。 05 局限与责任 谨慎前行的技术探索 尽管表现亮眼,Genie 3 仍存在明确的当前局限:智能体直接执行的动作范围有限,难以精准模拟多智能体复杂交互,无法完美还原真实地理位置,文本渲染能力不足,且连续交互时长仅为数分钟。 DeepMind 强调,基础性技术的发展必须以责任为前提。目前 Genie 3 仅以 “有限研究预览” 形式,向少量学者与创作者开放,旨在收集多学科反馈,持续完善安全措施,确保技术发展始终符合人类利益。 从文本描述到可实时交互的虚拟世界,Genie 3 为世界模型技术开辟了新边疆。随着技术的持续迭代,它不仅将推动 AGI 研究的加速发展,也将在教育、科研、创意等领域催生全新应用模式,让 AI 技术真正服务于人类社会的进步。
